The Service Discovery concept is not new and has been since from the beginning of distributed computing. In simpler terms, Services discovery tools help services to discover each other on the network. Comparing monolithic, microservice architecture tends to change more frequently and they need to be located anywhere in the cloud / on-prem. In other words, services and applications are required to be aware of other services on a network. Hence it is necessary for a microservice-based application architecture to have a service discovery mechanism, which is typically implemented using a service registry. The service registry (a.k.a discovery server) is used by microservice to publish their locations in a process called service registration and microservices will get help from the discovery servers seeking registered services and this process essentially called service discovery.
Note: Service discovery only allows healthy service to get live traffic and remove unhealthy services dynamically.
Service Discovery in early days
In very early days traditional distributed systems reside on a physical server(1:1 relationship between application and backend). In this case, we know the location of servers and to find the backend service by using static IP Address or DNS which will be configured in the configuration property file. The client will have access to the property file and connect with the respective backend.
Since one application with 1 single server is not scalable, In traditional models people used to have the application deployed in multiple physical servers. To find the actual endpoint to connect with servers, the Load balancer came into the picture which is the key to the story which acts as a broker between application and the backend.
When new instances are added in the backend, the service IP/Virtual IP was added in the load balancer and this task was performed by support guys many times whenever new instances got added. Also in the early days, most of the applications were not growing and shrinking too fast so it was manageable.
Why is service discovery needed?
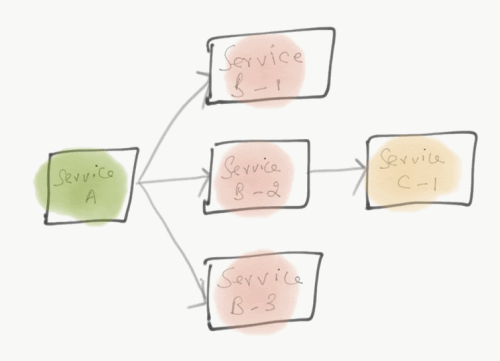
Basic question: What is the smallest subset of problems that we can usefully solve with Service discovery?
If you consider Monolithic architecture, it is less likely to change and mostly contains static configuration (Static IP, DNS, Load balancer configuration, etc), and when the change occurs developers can manually update and load the configuration file because they know where the service is deployed (location).
This will not be applicable for microservice architecture because microservices is updated more frequently and often scaled in/out based on the live traffic (real user traffic) and the load situation, so in this case, we cannot manually update the service information and it is not practical and doing that will lead to huge traffic loss and chaos.
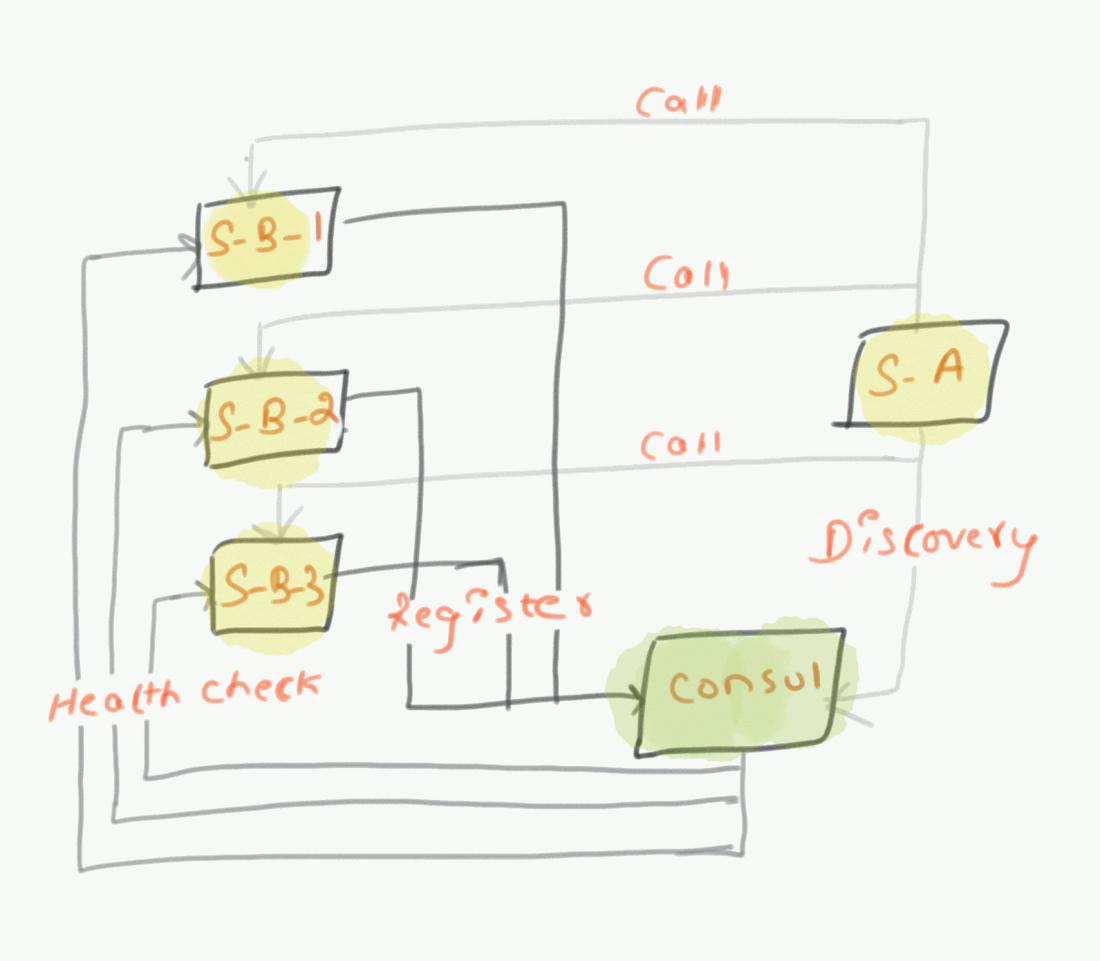
To get a better understanding, Let’s take a small use case where a number of microservices communicate with each other, Let’s say Service-A needs to communicate with Service-B-1 and so on. Now Service A needs to know the IP Address and port number of Service B that exists in multiple hosts.
Let us see how to solve the problem in 2 approaches
Approach 1 : Have the URLs hardcoded in the microservices.
If you consider this approach you have to find workaround for below problems.
- When the instances are autoscaled it will be a tedious effort to update the new URL in the configuration.
- We have to update the configuration every time the URL changes.
- Difficult to maintain details in configuration files.
- Error-prone if we are not managing it properly
- We cannot utilize the auto-scaling capability of the cloud to scale up/down based on the requirements.
Approach 2: Have service discovery implemented.
Advantages of considering this approach.
- All the microservices will register with the service registry with the IP address and port.
- Routes the calls to respective microservice which are healthy and active.
- Removes the service which is unhealthy.
Obviously approach 2 is the best solution to go.
When to use service discovery?
Service discovery implementation can be referred to before the Kubernetes era and after the Kubernetes era. Before Kubernetes era service discovery was implemented using external tools (refer below for the list of open-source service discovery tools). After the Kubernetes era many nonfunctional responsibilities such as health checks, service discovery, load balancing, etc … are by default built into Kubernetes. Refer to service discovery patterns in Kubernetes.
Possible use cases where we can use service discovery tooling is required to be deployed.
- When provisioning VMs based workloads either in cloud/On-prem, especially when the virtual machines are auto-provisioned to horizontally scale the microservices.
- Access keys/secrets and configuration related information can be managed through service discovery tools (key/value pairs).
- Non-Kubernetes services that are external to the cluster can be accessed in a native Kubernetes way.
- If you are having a Database Server deployed (ex: 1 master/4 Slave) which has a static (or) ephemeral IP address for master. Instead of hardcoding the Master IP address directly in the application, you can curl that information from the service discovery tool (ex: Consul). If master IP changes, you just update the IP address in the key/value store and don’t need to change anything in upstream.
Service Discovery patterns
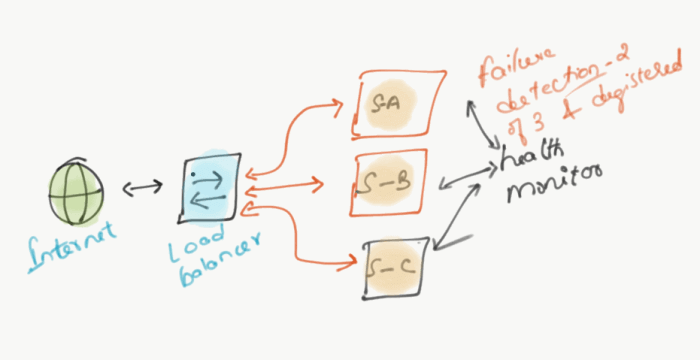
In a distributed computing environment, the microservices application will undergo massive changes. The changes being VM based workloads horizontally scale in and out, container auto-scaling, and microservices become healthy and inactive.
There are expected service outages and network issues which will cause the service to be unavailable and require particular service should be load balanced automatically to active services in the network. Service discovery will come into the scene for help and it is a key building block within microservice architecture.
Below are the two key factors and patterns that decide to service discovery is critical to a microservice.
Application Health Monitoring
In-Service discovery, the Service registry will enable a health monitor for the services running in the environment. Services can have health check endpoints built and it will interact with the service registry to report the health status. Identified status information will be eventually stored in the key/value store.
This pattern is most useful in monitoring databases and microservices, which are deployed across multiple hosts. It will also provide service health information to a client upon request and can initiate an action based on health results.
Application Resiliency
Service discovery offers the application team to quickly scale up/down the number of service instances in a distributed environment. Say when a service becomes unstable or unhealthy, service discovery engines will dynamically remove the unhealthy services from the list of internal services and route the request to the available or active service in the host.
This pattern will be most used with load balancing and microservices/middleware for availability.
How does the service discovery work ?
The concept is very simple, in practice, the microservice location may not be known at the design time, because microservice may be deployed in on-prem or Cloud-based systems which will relocate services at runtime. Therefore, we need a service registry (Discovery server) to keep track of all microservice locations. So that every service needs to be accessed by the other service that registers itself with a discovery server (friendly name IP + Port) E.g: app:{10.0.1.0: 8080}. This process of asking a discovery server for help to get a service that you need is essentially called service discovery. In that sense, we can more accurately called service location discovery, because you are discovering the location of a service.
There are two patterns in service discovery.
1. Client-side service discovery
2. Server-side discovery
Client-side service discovery pattern
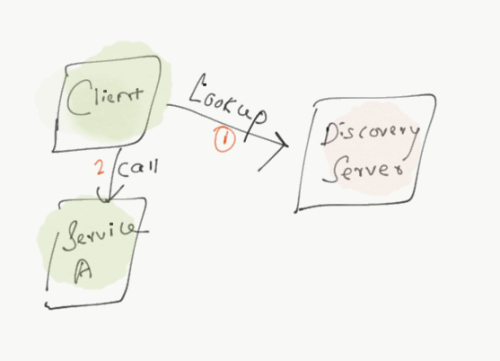
Instead of definition will start with an example to understand more easily (Reference for clientside discovery), Let’s say if your laptop was having some issue and you need to fix it. What you will do first, you search in google to find the nearest support guys phone number and you will book an appointment to fix the problem. The information you are trying to look at is nothing but service discovery. How? Google is acting like a service registry and you are the client to use the service registry to locate the service you need, which is the support contact information.
Who is doing all the work here to discover all the services? It is the client, and you tell the registry what you want and lookup for the support information and provides the details. In the case of microservices, the client-side microservice does the lookup, and with the discovery server to identify the location of the service it needs, then it makes a second request to the actual service itself. This is called client-side service discovery. It is obvious to make two calls, one to service registry and another to actual service.
Server-Side Discovery Pattern

Let us see an example to understand the service side discovery (Reference for server-side discovery). Assume you are trying to reach someone in an organization, the call will go directly to the front desk and they will be the one who will be redirecting the call to the appropriate person you are looking for. In this model the Client is not doing the magic and Server is doing the magic. The client actually sends the information about the service it actually wants to reach and the load balancer will check with the service registry and transport the request to the right destination. This is called Server-side service discovery
Two models of service discovery both doing the same thing pretty much-connecting microservice together and having them locate who and they call.
Open source Service discovery tools
There are a lot of open-source service discovery tools available in the market and we will see some of the most widely used tools and advantages. Please refer to the comparison chart of different service discovery tools.
etcd
An open-source is written in go. Etcd used for service discovery and key/value management. etcd is built on raft algorithm protocol, basically used for communication between Etcd machines. By default, etcd is inbuilt in all managed Kubernetes like Google Kubernetes, Openshift cluster ecosystem (OCP), and so on. No separate deployment setup is required. Etcd is connected with many projects on GitHub and used by many companies like Google, Kubernetes, rook, coredns, etc.
Some of etcd features
- Etcd designed specifically for distributed systems.
- key/value store accessible via HTTP.
- It is distributed by nature and has reliable data persistence.
- Data Persistence: etcd data is persisted as soon as it is updated.
- Etcd can handle the leader elections gracefully and tolerate machine failures, even in the leader node
- Etcd supports TLS & authentication through client certificates for the client to server/server to server/cluster communication.
- Good documentation support and the source code available on GitHub, and it is supported by Cloud Native Computing Foundation.
Consul
An Open Source is written in go. Consul is a DNS based service discovery tool, enabled to discover, automate, and secure applications across distributed systems on cloud and on-prem. It also provides a built-in framework for service discovery health checking, failure detection, and DNS services. Clients need to register services and perform discovery using DNS or HTTP API Interface. It uses a different algorithm called “SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol” (SWIM) for its distributed computing model.
some of Consul features:
- Hierarchical key/value store.
- Consul provides both Service discovery and acts as a DNS Service.
- Consul exposes restful HTTP APIs, it can perform basic operations like create, read, update and delete on nodes, services, and so on. It is also easy to write to clients from any language.
- Clients can easily query Consul HTTP API using the key/value store to identify which server is the cluster leader. ($ANY_CONSUL_SERVER/v1/status/leader)
- Provides dynamic load balancing. It can resolve configured third-party load balancers like (F5, Nginx, HAProxy) with a list of IPs for each service and update the list of IPs automatically when required.
- Seamless integration with HashiCorp Vault
- User-friendly Consul WebUI for visualization of service and node health which ease troubleshooting for new users.
Consul provides both Service Discovery and DNS but that isn’t true of all SD products like Zookeeper, etcd, etc.
Zookeeper
An Open Source is written in Java, It is similar to etcd and solves the same problem. It originated in Hadoop and deployed as part of Hadoop clusters and Kafka stacks and has proven to be resilient. Similar to etcd, zookeeper uses a custom protocol named Jute RPC, is totally unique to zookeeper and limits its supported language bindings.
Zookeeper is the not most widely used product in the service discovery field, meaning when zookeeper master nodes fail to connect with other nodes due to network issues, will cause the registration system service to paralyze during the election. Meaning, you should at least have 3 nodes running to ensure the data is replicated and highly available when the node fails.
some of Zookeeper features
- Hierarchical key/value store
- In memory file system mode
- Distributed notification and coordination
- Distributed locks and queues
- Znode. Nothing but data nodes and each data node in the cluster can hold a fairly small amount of data that is versioned and timestamped. The versions will get increments based on the data changes in Znode.
- Ephemeral Znodes: The ephemeral node exists for the lifetime as long as the session that created the Znode is active. Znode will be deleted when the session ends
- Watches: Changes in the data node (Znode) will trigger Watch. When the watch is triggered it will send a notification (Znode has changed) to the client. More information about watches can be found in section ZooKeeper Watches.
Zookeeper is used as part of apache projects like Hadoop, Hbase, Kafka, NiFi, Solr, Hive, etc and some examples of platforms that are built-in with zookeepers are Kafka, HBase and etc.
Eureka
Eureka is written and open-sourced by Netflix and mainly used for service discovery and key-value management. It can integrate with spring cloud configuration servers. Eureka architecture consists of two main components, a server, and a client. The Client will act as a polling load balancer to support service failover and ease interaction with the server. The server is generally used for service registration.
Let us take an example, say Client A and Client B are registered in the Eureka server. If any of the two services want to talk with each other, it can obtain an IP address and port via the eureka server.
Eureka adopts a decentralized design concept. The entire cluster is comprised of peer nodes and because of this, there is no need to elect a master node in case node failures. The failed nodes will not affect the availability of normal nodes to provide the service registration and service query
Spring Cloud Configuration Server
An open-source project that offers configuration management solutions for different backends like Eureka, Consul, GIT, etc. It tightly integrates with Spring Boot but is easy to set up and read all of your configuration data with simple annotations.
My Two Cents
- etcd and Consul solve different problems: Consul is recommended to implement for a VM based workload environment and If you are looking for an end to end cluster discovery (key-value store, service discovery, dynamic load balancing, Service mesh support, MTLS encryption … etc)
- You can especially go for consul for leader election or distributed semaphores for distributed systems in cloud/on-prem.
- etcd is a standard service discovery that is built with Kubernetes based container management platform. If you are looking for a distributed key-value store, etc is the best choice over consul.
- Zookeeper is old by now and doesn’t provide us service discovery functionality out of the box compared to new alternatives (consul, etc) which are referred above.
- Eureka 2.0 has been discontinued and no longer maintained, Its current codebase and functions are already stable. Eureka 1.x is still active and these functions are sufficient for service registration and discovery.
Conclusion
Service discovery is a key building block within microservice architecture. The most common tools used across the industry include consul, etcd, Eureka, Zookeeper, etc.