English writer and philosopher “Aldous Huxley” once said: “Speed provides the one genuinely modern pleasure.” I think life is like this and so the software field. With the rise of DevOps, DevSecOps, MLOps, AIOps, Gitops, and other practices, the speed from requirement gathering, design, code deployment to production is getting faster and faster.
What is GitOps?
GitOps was originally derived by Weaveworks co-founder Alexis Richardson in August 2017. GitOps is a model to achieve continuous delivery and using Git development tools to operate and manage cloud native applications. In simpler terms, If you want to deploy a new application or update existing application running in the cluster, you just update the Git (configuration repository) – the automated process (Operator) will observe the environment and if it is inconsistent with the state in Git repository, it will automatically restore to a known state from Git.
Refer post: DevOps
Definition of GitOps
GitOps provides a way to automate the infrastructure configuration process. It adheres to the philosophy of DevOps (you build it, you ship it) best practices such as version control, code reviews, and CI/CD pipelines.
Benefits of GitOps
Applying the GitOps to Continuous delivery has many advantages, including below
▌Develop faster
The idea of the GitOps model is to allow developers to deploy applications and their corresponding IAC file sets to cloud-native environments such as Kubernetes, which also helps in improving business agility, and faster product delivery and, average recovery time.
▌Better operation and maintenance
With GitOps, not only a complete end-to-end pull-type continuous integration pipeline and a continuous deployment pipeline can be realized. It also results in better operation and maintenance of the system by having infrastructure configuration + Application code of the system in Git.
▌Strong security guarantee
Almost all GIT middle libraries provide role and permission control, and those who have nothing to do with development and operation, and maintenance have no right to operate GIT middle libraries.
▌Easier audit for compliance
Every change of the system corresponds to a git commit and any change in behavior can be audited, Say if someone unintentionally modifies the system, we can compare the cluster desired state with the actual running cluster (Current state) and can be restored to the desired state at any point in time.
Why choose GitOps?
One of the main benefits of using GitOps is its self-healing nature. Since git is the source of truth for the entire system, if someone inadvertently modifies the system, it will be restored to keep in sync with git at any time.
Similarly, in this case, rollback is also easy. In most cases, the main branch reflects the state of the system. If there is any kind of failure in the application and it needs to be rolled back, you only need to restore it to its previous git state.
Since all operations are done through pull requests, it also solves the issues of audit trail and transparency. If something doesn’t work, you can look it up in one place, the submission history.
How GitOps Works?
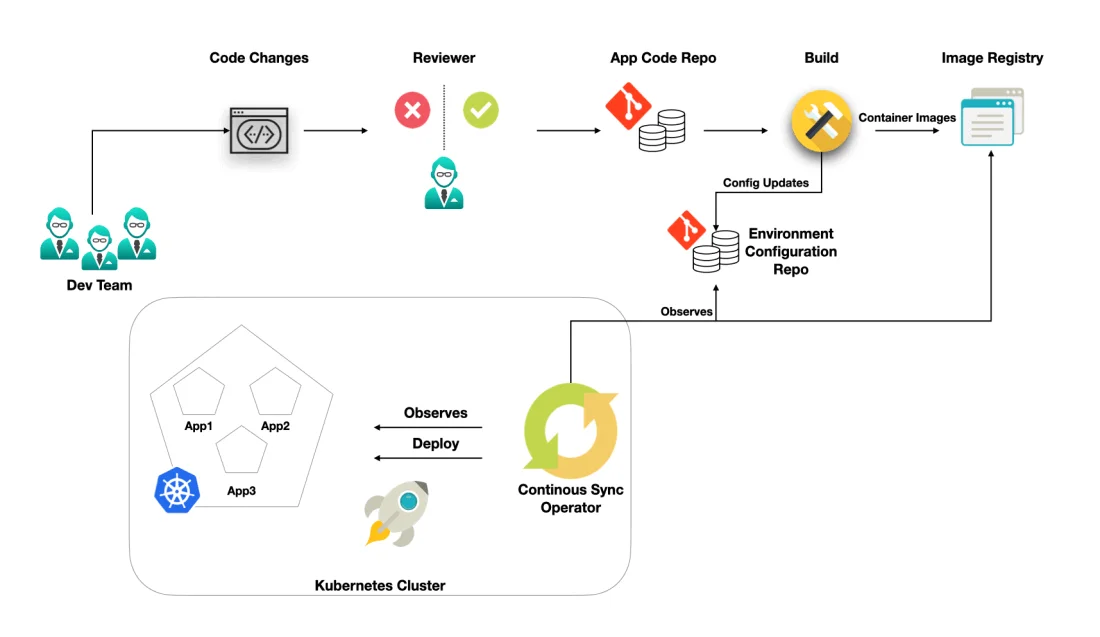
GitOps and CI/CD are working partners. CI/CD allow developers to continuously iterate, develop and deploy applications. Here the iteration is carried out by Git Configuration repository (you can use Git or GitLab or any other version control system). In the Continuous Deployment/Delivery phase, Git organizes the application repository which contains source code and environment configuration repository which contain deployment manifest to deploy the application.
When you push a change to the application repository, the automated pipeline will run unit tests, build a container image and push it into the image registry. After pushing the image, it updates the environment repository. In turn, the “operator” software process that lives inside the cluster will check the operating state of your application, if it finds inconsistent with the state in Git repo, it will be restored to a known state from Git.
We have two ways to implement the delivery pipeline (Push and Pull Mode) for GitOps, we will see why GitOps prefers to use the pull mode to build the pipeline.
Push Model
The complete explanation of CI/CD is actually beyond the scope of this article. For better understanding google CI/CD, you will get millions of articles. In short most, CI/CD tools build delivery pipelines based on the push model. The push-based pipeline means, whenever the application code is updated into the main branch, the build pipeline triggers CI system, followed by a series of unit tests, code quality, and regression test suite, finally builds container images and pushes to the repository, and finally to the environment.
Although this method has a high degree of automation, and the advantage of using this method will suit any kind of infrastructure and but it has some of the disadvantages listed below
- If the system fails after completing a deployment through a CI task, how will you know which version to roll back to? You may need to carefully check the build log to find the version and rollback operation will be a little tedious.
- How will you determine the version of each application that needs to be deployed when the cluster is completely collapsed? You may need to re-run the CI task again and it is difficult to rebuild the cluster quickly?
Pull Model
The pull model enables developers to maintain the desired infrastructure configuration + Application code of the system in Git and an “operator” software process that lives inside the cluster is responsible to change the current state to the desired state of the system.
Below are the following high level steps to perform a new release with GitOps model
- Commit the code (Git) containing new features to the master branch via pull request.
- After the code is approved, it will be merged into the Master branch.
- The merging behavior will trigger the CI system (eg: Jenkins X, Travis CI, CirclecI … ) to build a docker image and perform a series of unit tests.
- Once the build is successful and the image is created, the CI system will push the docker image to Docker Registry (eg: Docker, Quay, Jfrog, Nexus) and update Git Repository (configuration repository)
- GitOps operator (ex: Weave Flux/ArgoCD .. etc ) runs on the cluster which will compare the current state with the desired state as specified in configuration repository.
- Once it detects the cluster state is not in sync with the desired version, it will pull the updated list from the configuration repository and deploy the image containing the new function to the cluster.
What does GitOps bring?
- In the Kubernetes platform, Git provides the only source of truth for application development, operation and maintenance.
- GitOps provides an operation model for applications to unify the operation and continuous development of applications.
- As part of the CI/CD pipeline, GitOps provides the glue between the application build/delivery and the location where it runs.
- Git can control rollbacks, upgrades and changes.
- Git controls and fixes differences or “drifts”
- GitOps uses auditing, monitoring, and rollback functions to increase the reliability and stability of application releases
GitOps Tools in the industry
GitOps is not specific to Kubernetes, the same principles can be applied to any declarative configuration management environment. We have many products in the market like Weave Flux, Jenkins X, and Argo CD, which are matured enough to automatically harmonize the state of your cluster to match the config in the Git repository.
Conclusion
From my experience, achieving enterprise-level Continuous Delivery is not a big challenge unless you are locked to specific software delivery methods. In Short, GitOps is a good workflow model that can help you to deal with cloud infrastructure efficiently and it also provides many advantages to engineering teams, including better coordination, transparency and stability.
References
1. https://www.gitops.tech/ 2. GitOps - weaveworks 3. GitOps - Cloudbees 4. GitOps - Gitlab 5. GitOps - Openshift 6. GitOps - codefresh