Data engineering is more of a common term today and traditionally it is also being referred to as ETL, BI, and Big data developers. Modern Data Engineering in cloud platform ought to support fully developed and operationalized data pipelines which should be cloud-capable and run on modern, distributed execution platforms. It further supports machine learning, analytics, data quality, security, and adhering to securing PII information, for compliance with GDPR and other regulatory frameworks.
Big Data and AI Executive Survey 2022
NewVanage Partners has surveyed 94 Fortune 1000 and industry-leading organizations that participated in the 2022 survey to understand the transformational impact that data would have on their organizations and industry.
In short, the outcome of the survey indicates that 97.0% of participating organizations are investing in Data initiatives and 91.0% are investing in AI activities. Further, 91.7% of organizations report that their investment in Data and AI initiatives is increasing.
This year, 92.1% of organizations report that they are realizing measurable business benefits, up from just 48.4% in 2017 and 70.3% in 2020. More than half of organizations have developed a corporate data strategy – 53.0%, and 59.4% report that these strategies are yielding results. However, organizations still face challenges in their efforts to become data-driven.
More info can be read in the following survey summary.
What is bigdata ?
Big Data refers to the collection of data that cannot be captured, managed, and processed with neither traditional storage systems such as relational database management systems (RDBMS) nor conventional software tools within a certain time frame.
This resulted in the need for new approaches leading to the creation of Google File System, MapReduce, and BigTable(2006) by Google. The computational challenges and solutions spoken in Google’s paper provided a blueprint for the Hadoop File System (HDFS), which is implemented by itself based on MapReduce and Google File System.
How is Data Engineering related to Big data?
Earlier data is stored across on-premise clusters and data warehouses within the organization and in the longer run, it resulted in incurring heavy cost and maintenance associated with the infrastructure and data. To overcome that organizations were strategically investing solutions on cloud-based infrastructure to deal with the huge data which allowed them to store, scale, integrate, and deliver insights to the organization’s growth.
So the path forward for the organization is to rely on cloud-based infrastructure for data storage, create pipelines for the data, transform and expose it for analytics. To modernize data pipelines and manage the workload in cloud-based infrastructure, organizations required expert Data engineers/Data scientists/DevOps with specific skill sets to manage the data, customized codebases, and infrastructure.
By having this approach we can reap the following benefits
- Scale in and scale out the cloud resources as when needed. It ultimately results in the Pay Per Usage model.
- Reduced operation cost and complexity of data management.
- Increased agility.
- Easy to spin up new environments, load, transform and consume data insights.
Role of Data Engineer
A professional Data Engineer ‘helps’ to collect, curate, and aggregate data from various data sources and create a consolidated data platform that empowers data-driven decisions for an organization to leverage business.
The consolidated data in the data lake/data warehouse satisfies hundreds of consumer use cases, feeds the BI reports, empowers the data scientist, trains the machine algorithms, and so on.
A typical Data engineer will have the skillset of a Software Engg + Business Intelligence (BI) engineer including Big Data capabilities. I am borrowing the definition of data engineering from Book (The Data Gaze: Capitalism, Power and Perception | Author - David Beer) "The data engineering discipline also integrates specialization around the operation of so-called “big data” distributed systems, along with concepts around the extended Hadoop ecosystem, stream processing, and computation at scale."
Data science vs Data engineering?
The data architect and data engineer work one behind the other. Meaning, Data architect will conceptualize & design the Data platform Framework and the Data Engineer will take care of the implementation part. The data architect & data engineer roles will concentrate on designing data platforms and consolidating the data (Model, Collect, Cleanse, Transform).
Data science is a research portion and Data engineering is a development portion that definitely works hand in hand. Data science (more kind of exploratory type of problem) will look for patterns in data and predicts a better solution about what is the value of the data for leveraging the business. In other words, data scientists will focus on finding new insights from the curated data.
Modern Data Engineering in cloud
The only constant in the software industry is Change. But the fundamental principles remain the same. That is true in the case of Data engineering. Today data engineering always differs from the old methodologies in terms of collecting, curating, and aggregating data. When I started practicing big data years back, we were using tools like Informatica, IBM Datastage, MapR, SAP tools, Pentaho ETL, Talend, etc.
But today this Isn’t the choice for modern Data Engineers today. Let’s discuss an example with respect to Storage layers (Data lake/Datawarehouse) and Transformation layer (ETL).
A. Storage Layer
Years ago data warehouse was maintained inside the organization on-premises and managed data connection to applications that are running on-premise as well. Generally, the organization used traditional ETL tools for connecting through the ERP systems/CRM systems and delivering the data to the warehouse.
With this model, many organizations are not satisfied because they were not getting the value at scale in a responsive way from a data warehouse/data lake. So naturally, Paradigm Shift happened from on-prem to cloud and that model has changed quite dramatically with the cloud today.
With the cloud providers, you can manage your services easier at a lesser cost, and you can get the value of data at scale from the data warehouse in the cloud and following are storage options more frequently used in the cloud – Amazon s3, Azure Data lake storage, Google cloud storage.
B. Transformation Layer – (ETL)
Traditional ETL tools are largely obsolete because the logic cannot be expressed using code and these tools have been replaced by programmatic or configuration-driven tools provided by cloud providers like Google Cloud, Azure, AWS in the industry. Each cloud provider has plenty of options to perform all operations in terms of collecting, curating, and aggregating data.
Also, organizations today prefer cloud-based solutions to get quicker results with less overhead and maintenance at a later point in time. Meaning, You can perform Data Extraction using custom code written in Python, Go, Java.. etc and on the other hand using managed options like Amazon Kinesis (AWS), which has the capability to do the same job, and you can get timely insights and react quickly to new information.
Also, you don’t need to worry about scalability and availability just configure the endpoints and get the data with less turnaround time. It also supports sudden traffic spike burst and scale in/out data pipelines automatically with ease. Those are the things that make modern data engineering today.
Today most Data Engineering job opportunities are associated with the Top 3 cloud providers and the job title would look like below
- Google Cloud Data engineer
- AWS cloud data engineer
- Azure cloud data engineer.
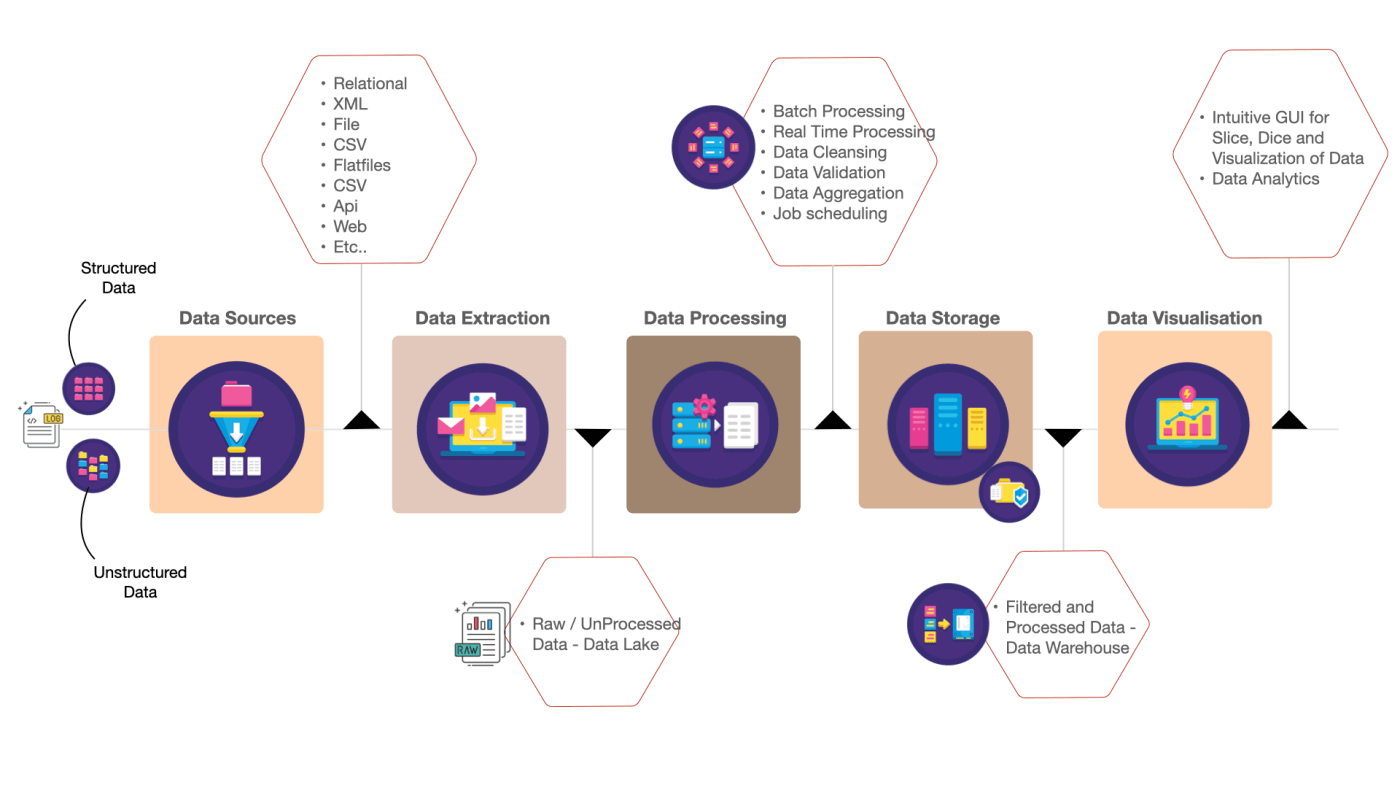
Data Pipeline Stages
Data Engineer will primarily work on the below-mentioned Data pipeline stages. From my perspective, more complex scenarios will be addressed in the Data Extraction and Data Transformation Stages. Below are the data pipeline stages explained at a High level.
A. Data Extraction
The goal of this stage is to extract data from internal and external sources. In a typical use case, the following would be data sources that you might be extracting the data (Relational, XML, File, CSV, Flastfiles, APIs, Legacy systems, Proprietary software, text files … etc).
The data will be extracted into a repository called Data Lake. In Industry terms, the extracted data is called as Unprocessed data (or) Raw data (or) Golden data. The extraction will fall into two categories Real-time data processing and Batch data processing.
B. Data Transformation – High level
At a high level, This stage involves the validation and transformation of the data and storing the end results in formatted output in any of the following formats – JSON, CSV, AVRO, ORC, and Parquet.
The typical transformation will be similar to performing Anomaly detection, Metadata management, Deduplication, Data Validation & Cleansing, Data Aggregation, and Change Data Capture with the collected data.
C. Data Curation
The goal of this stage is to enhance the quality of data before the data is stored into the target by applying various techniques to curate the data, some of the common techniques are
- Deduplication – Remove identical duplicates
- Missing/Null values – Rows/Columns with missing values will be eliminated from processing further or have the default values from Master data.
- Standardize values – If you columns contain values such as data123 then it has be considered as categorical or numerical depending on the business use case and similarly normalizing numbers, text values according to the business requirements.
- Failed Records for reprocessing/review
- Auditing Data Processed.
- Total Count/Processed Count/Failed Count and thereby enriching the overall quality of data.
Note: Sometimes based on business use cases we used to convert rows to columns and vice versa as part of transformation & sub transformation.
D. Data Transformation
The goal of this stage is to convert data types, define how different data fields will be mapped, aggregated, filtered, or joined to make sense out of structured and unstructured data for analysis. Add more information such as date/timestamps, geographic locations to the data to enable efficient lookups and form a better hierarchy.
These transformation activities are performed in a staging area called Data Staging (typically another storage bucket on the cloud) before the data gets loaded into the target database/data warehouse.
E. Error handling & Retries
Errors can occur in various phases starting from data extraction, validation, and or while parsing the data, or during the transformation, or during the final insert into the database/data warehouse phase will be recorded in a separate collection.
This will help us in various purposes like backfilling delta data (CDC) at a later point in time with the right values and also finding & eliminating bad records as well.
F. Data Validation/Auditing
The goal of this stage is to ensure all the required dataset is present by performing comparisons between the source and target. In addition, schema validation/conversion is performed to ensure the overall health of the data, and changes (if any) that will be required in the source data to match the target schema.
Subsequently, a review and audit (can be done programmatically or using enterprise/open source tools) are performed to check if there are no anomalies or discrepancies. Based on the result, a decision on whether to move forward or re-run one of the previous stages will be decided.
G. Change data Capture
The CDC methods will enable you to load only the delta data or changed records from the data source rather than loading the entire data.
Let me explain with a simple scenario, Consider the ETL pipeline has processed 1 million records and out of that, you haven’t processed 100 records due to missing values in the records. At a later point in time, if you are receiving the delta records, your ETL pipeline will be designed efficiently to identify and capture the incremental data that has to be Updated/Added/Removed from appropriate database tables.
This refers to Change Data Capturing. Delta data will be further processed and used in the Data analytics stage to get more accurate insights into the data.
H. Data Storage
Once the data is Curated, it will be consolidated into a data warehouse (persistent store), which will contain processed data. Generally, the transformed data would be saved in any of the following formats JSON, CSV, AVRO, ORC, and Parquet
I. Data Visualization
Data visualization is nothing but viewing the processed data in the form of graphs charts and maps. BI tools will provide different views like trends, outliers, and error patterns of the data. The main goal is to analyze massive amounts of data and find useful insights into the data.
When is a Data Engineer Needed?
There is no requirement to have data engineers in every organization.His/Her skills are mostly required if the company either:
- Having a large amount of data.
- An organization should need or desire to analyze the data from various kinds of sources.
- Last but not least, An org should have half a million to do all this 🙂
Skills required to become a Data Engineer
What does a data engineer need to know? What areas does she/he require to learn and improve the skills? – In the first place, Data engineers need to have good exposure to different big data technologies and they should have the capability to trade off the right toolset and technologies to get the job done, based on the business goals and objectives.
Below is the typical road map to follow one to become a Data engineer
Data Engineer Roadmap
A. Learn Data Modeling Concepts
The data modeling will classify the characteristics of the data in the database and all other components. Below are the highlighted areas where you need to have an exposure
- Conceptual Data Modeling(CDM): This data model includes all major entities, relationships, Meaning only high-level information of the entire model and it will not contain much detail about attributes and this will be input to the second model
- Logical Data Modeling(LDM): This is the actual implementation of a conceptual model. A logical data model will clearly show the data entities and relationships between them.
- Physical Data Modeling(PDM): This is a complete model that includes all required tables, columns, relationships, database properties for the physical implementation of the database.
B. Learn Architecting Distributed Systems.
In simple terms, it is a set of computers communicating with each other over the network and getting some coherent tasks done. Just explore use case studies around storage and Big data computations and peer-to-peer file sharing.
The reason why this is important is a lot of critical infrastructures out there is built out of distributed systems. For more info watch this video.
C. Cloud platforms tools
- Amazon Web Services
- Google Cloud
- Azure
Get yourself, master, in any one of the aforementioned cloud providers, Concentrate and focus on tools related to data pipeline operations like Data Extraction (Real-time/Streaming), Data Transformation, Workflow Scheduler, Data Storage, Data Visualization, Monitoring, Data Governance/Cataloging, Deployment, Data Security.
D. Big data Tools
It is a common requirement to have a base knowledge in the Hadoop ecosystem and apart from that, you need to gain an understanding of the frameworks below listed.
- Hadoop (HDFS, MapReduce, Hive, Hbase, Drill, etc)
- Spark (Streaming RDD, Spark SQL, Spark DStreams, Spark Syncs/Connectors, Spark Executors, Spark Scheduling, Spark Submit, Distributed Data Transformation, and Processing)
- Message Queuing Technologies (Apache Kafka, ActiveMQ, RabbitMQ)
- SQL/No-SQL system and queries (SQL/DML/DDL)
How to Install Hadoop on Mac
E. Programming language
Newbies can start with python, simple syntax and you can learn easily it is great for all range of data analysis tasks. Scala is designed for parallel data processing and is effective in handling large datasets.
- Python – Pyspark/ Pandas/ SciPy / NumPy
- Scala
F. Workflow Orchestration
Big data workflow is involved in the execution of tasks in a particular order and most of the time we do repetitive tasks. This can be addressed by doing proper workflow Orchestration.
In earlier days I have used oozie and used to write workflow definitions in XML and it was not programmatic. Due to various limitations, I’ve written my own scheduler which is in python, and used PostgreSQL (database) to save our state (job management).
The state will have the details of workflow start, whether it is progressed or failed will be saved. Now you don’t have to struggle that much 🙂 explore the below tools that should suffice your needs.
- Airflow
- Azkaban
- Luigi
Data engineer responsibilities
The main responsibilities of a data engineer are to collect, manage, and transform the data from multiple sources into a format where it can be easily analyzed.
A typical data engineer should possess good knowledge in the below areas
- Data Collection Frameworks
- Hands-on building ‘big data’ data pipelines, architectures, and data sets.
- Working knowledge of message queuing systems (Apache Kafka and its producers and Connectors).
- Data Processing/Wrangling-Cleansing & Transformation Frameworks.
- Relational SQL and NoSQL databases Systems and Queries.
- Data Lake/Warehouse development and processing
- Experience with big data toolset – Hadoop Ecosystem – HDFS, MapReduce, Hive, Hbase, Drill, Spark 2x/3x Ecosystem and Development, Workflow orchestration tools.
- Experience with Cloud services – AWS (or) Google Cloud (or)Azure.
- Best Practices on Data Movement, Storage, Processing, Analytics, Cost Efficiency, Scaling / Resiliencies.
My two cents on Data Engineering
- Use transient clusters (Compute clusters will automatically terminate/stop when the job/steps completed) for Batch processing.
- Start testing phase as early as possible – This will help you to find the bugs in your data pipeline stages. Moreover, if you are using commercial off the shelf applications (COTS), it will be easier to mitigate the risks and limitations (if any) asap.
- Plan Disaster Recovery/High availability and get it tested and documented.
- Have a frequent Performance Load test to check the environment behavior and benchmark the results.
- Always preserve the injected (raw) data in the original form. This approach will allow you to repeat the ETL process in case of failures and other purposes.
- In terms of data storage simply store your data in the optimal tier to save cost each month. The right storage tier can be decided based on two parameters: i) its format and ii) how often it’s accessed.
- Data Security – Have the data Encrypted on rest/fly and Access all passwords/keys from a centralized mechanism.
- Data governance – It is not part of the data engineer bucket but to manage data you need to have a defined set of processes, roles, policies, and standards to access the data.
Data Engineering certifications
Data Engineering on AWS – AWS Certified Data Analytics – Specialty
The AWS Certified Big Data – Specialty certification validates individuals’ technical skills and experience in designing and implementing amazon services to derive value from data.
What does this certification validate?
This certification validates individuals’ understanding of using AWS data analytics services to design, build, secure, and maintain analytics solutions that provide insight from the data.
Note: Exam guide to prepare for AWS Certified Data Analytics – Specialty exam.
Data Engineering on Google Cloud Platform – Google Professional Data Engineer
A google professional data engineer certification validates individual potential to design, build, secure, and monitor data processing systems with particular importance on scalability, security and compliance and reliability, and portability.
The Professional Data Engineer exam evaluates your ability to:
- Design data processing systems
- Build and operationalize data processing systems
- Operationalize machine learning models
- Ensure solution quality
Note: Exam guide to prepare for Google Professional Data engineer exam.
Data Engineering on Azure – Microsoft: Azure Data Engineer Associate
Azure Data Engineers design and implement the management, monitoring, security, and privacy of data using the full stack of Azure data services to satisfy business needs.
Take these two certification exams and earn – Microsoft Certified: Azure Data Engineer Associate
Note: Exam guide to prepare for Azure Data Engineer exam.
Conclusion
Getting to speed and scale at cost is what modern data engineering in the cloud is all about. Today organizations need speed, processing power, scale, and performance to deal with big data. To manage the same we need Data engineers/Data scientists/DevOps skillsets.
The main goal of data engineers is to provide a reliable data infrastructure and help organizations to make the best use of the massive amounts of data collected and analyze the data from multiple sources and present it in easily digestible ways.
Data Engineering Online Courses
1. AWS Certified Data Analytics Specialty


Well, articulated content. I really like the skills part! Thanks
Thanks Mike