At present Data Engineering has become so popular and it is acting as the backbone for many companies like Google, Uber, Amazon, Tesla, etc. Also, companies are finding more ways to get meaningful insights from the data to prevent threats, understand their business more, predict the future of their business and their customers, and Data engineering is the anchor in all these activities. In this article, we will see what is the difference between Hot, Warm, and Cold persistence in terms of the data engineering world and what is the point in having such classification different.
Refer Post on Modern Data Engineering on Cloud
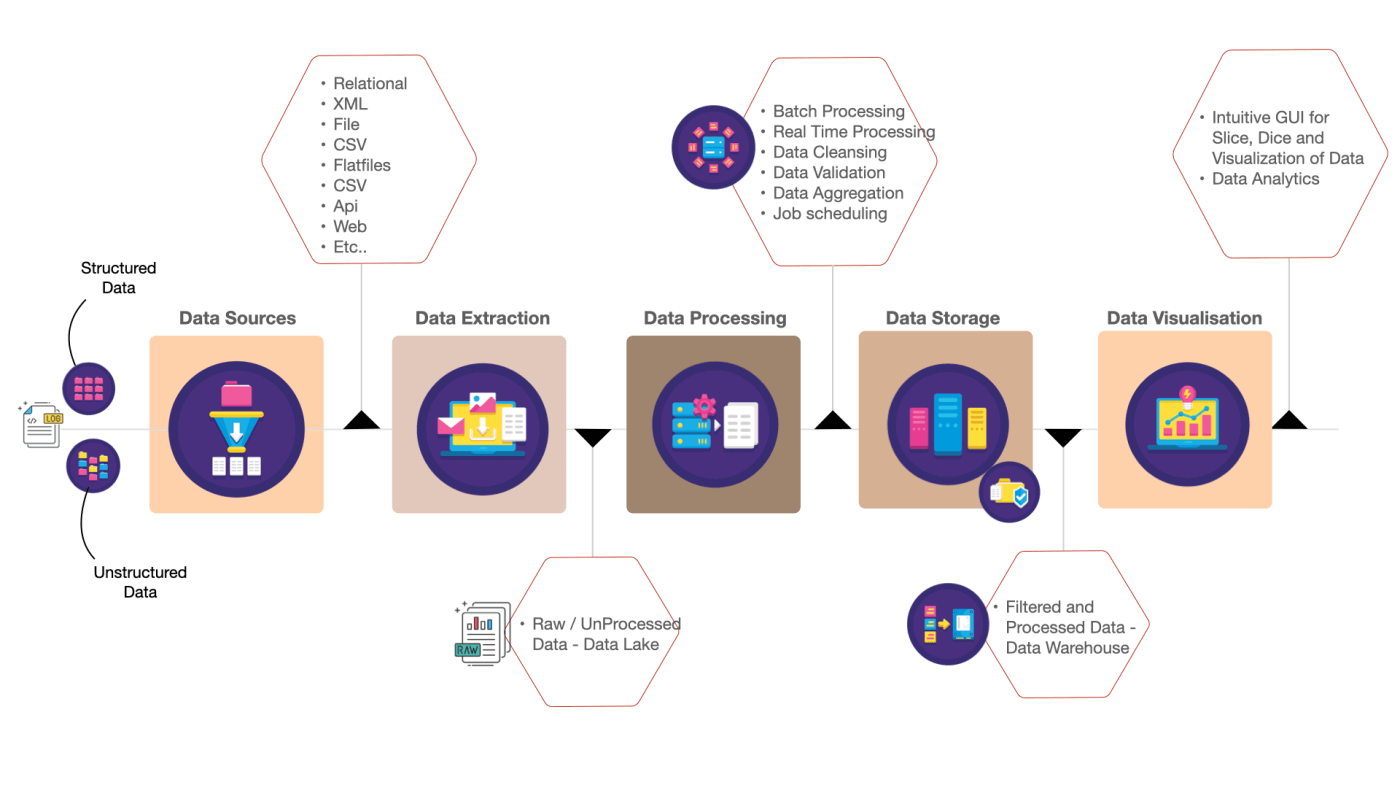
Lifecycle of Data Engineering
Before going into the persistent storage option we will see where it fits in the life cycle. Typically, In data engineering, the lifecycle of data is categorized into three steps, such as Extract, Transform and Load a.k.a (ETL).
The Extract stage will acquire data from many internal and external data sources based on the requirement and store the data into a preferred storage location in the preferred format (JSON, CSV, AVRO, ORC, and Parquet) in an incremental fashion. Once the data is collected the Transformation stage will cleanse/curate the data and load it for visualization and analytical purpose and utilized by the downstream components.
Once the data is extracted (a.k.a “Raw” or “Golden Data”), it will be persisted in different types of data storage options based on the project requirements. The storage options must be highly available and should be accessible to any regions where the application components are deployed in.
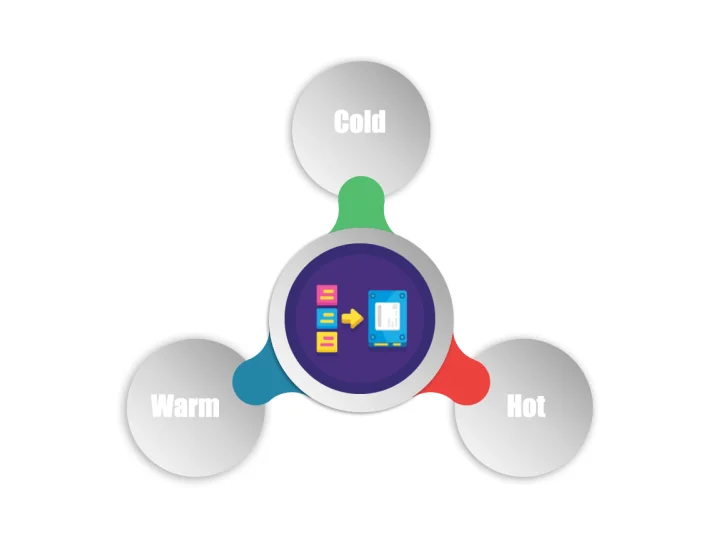
Hot, Warm, and Cold data storage difference
As per the organizational policies, the data should be retained for minimum and maximum retention period based on the project requirements and moreover it acts as a single source of truth (Golden data) which will be used for various reporting purposes and downstreams inside the organization.
So while choosing the storage tiers, we have to choose based on the usage patterns to optimize the storage cost. Because it is recommended that you have to consider your storage for your analytics applications and choosing the right storage layer for your workloads to achieve the desired scale.
Hot Data
- We can term “Hot data” as real-time data and It will have the most recent translational data and used for current reporting purposes. (Interactive workloads)
- Ex: Mission critical data (Transaction Data) used for current reporting purposes.
- It will always tag frequently accessed data and business will always use this data in constant for the analysis.
- The only criteria are, It should be highly scalable, queries need to fast and should retrieve data within 1s to 5s (Approx)
Warm
- We can term “Warm data” as Infrequently accessed data.
- Ex 1: Reference tables (country code). Ex 2: Transaction data older than a week
- It is not real-time, but data should be retrieved between 5s to 30s (Approx).
- The data should be highly scalable, less fresh data and queries are accepted to be a little slow in terms of performance.
Cold
- Opposite to Hot. We can term “Cold data” as less frequent update data or data that is never accessed (rarely)
- Ex: The data will be used mostly for ad-hoc reporting. Ex: The data is maintained for regulatory reasons and audit purposes.
- Low concurrency
- Usually, cold storage will be considered for long terms storage and slow queries are ok in terms of retrieval.
Real-time Mapping on Hot, Warm, and Cold data storage with AWS s3
AWS s3 offers different storage options which is used widely across industry as a cloud storage solution. S3 storage is the perfect fit for any data storage requirements and it offers a lot of capabilities to manage your data through its lifecycle. Based on the lifecycle policy, the data will be moved to different storage classes without any changes to your application. Also AWS s3 is a highly scalable object storage solution offering 99.999999999% durability.
- AWS S3 Standard can be used to store (Hot data) data that can be used frequently across different enterprise applications.
- AWS S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-Infrequent Access (S3 One Zone-IA) can be used (Warm Data) to store less frequently accessed data across the enterprise applications.
- AWS Amazon S3 Glacier (S3 Glacier) and Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) can be used to archive (Cold Data) rarely accessed data for long-term and audit purposes.
Conclusion
Hot data will operate on fresh data. Cold data will operate on less frequent data and used mainly for reporting and planning. Warm data is a balance between the two.